The APWG (apwg.org) is periodically asked our thoughts on issues of great importance to the cybercrime fightin’ community.
Background
After the Twelfth United Nations Congress on Crime Prevention and Criminal Justice, the Commission on Crime Prevention and Criminal Justice established an open-ended intergovernmental expert group to conduct a comprehensive study of the problem of cybercrime and responses to it by Member States, the international community and the private sector, including the exchange of information on national legislation, best practices, technical assistance and international cooperation, with a view to examining options to strengthen existing and to propose new national and international legal or other responses to cybercrime. The open-ended intergovernmental Expert Group to Conduct a Comprehensive Study on Cybercrime has held five meetings to date, respectively from 17 to 21 January 2011, from 25 to 28 February 2013, from 10 to 13 April 2017, from 3 to 5 April 2018 and from 27 to 29 March 2019. At its fourth meeting, the Expert Group adopted the workplan of the Expert Group for the period 2018-2021 (available at: http://www.unodc.org/unodc/en/organized-crime/open-ended-intergovernmentalexpert-group-to-conduct-a-comprehensive-study-of-the-problem-of-cybercrime2018.html). In accordance with the workplan, in 2020 the Expert Group will discuss international cooperation and prevention. Moreover, no later than 2021, the Expert Group will hold a stocktaking meeting and discuss its future work.
Our Submission to the Meeting
The upcoming Expert Group meeting will discuss a topic important to the APWG and its members: international cooperation. I have many thoughts about this topic and i want to share the two main points I submitted to the upcoming UNODC meeting in Vienna.
We Need Commonly Accepted Definitions
First, we need to develop a common definition for data that requires special handling or treatment. Every new regulation or directive has different – or new – definitions for data items that the regulators deem private, sensitive, or scary. For example, the definition of personally identifiable information (PII) varies among EU regulation and many other states. Sharing data globally to detect and apprehend e-criminals is near impossible when you must change the data record every time it is shared to national law enforcement authorities or private crime investigators. A common definition for special data would allow investigators and enforcers in multiple states to get the same data at very fast speeds. Aligning the various definitions is a daunting task – and may take a while – but lacking such commonality is definitely slowing down e-crime mitigation, investigation, victim reduction, and apprehension.
The Crime Fightin’ wall is really a tripod.
Secondly, many privacy and data sharing regimes have a specific carve-out for public bodies doing crme investigation. For example, the EU GDPR has two versions one for such bodies and one for “everyone else”. Many studies show that over 95% of internet-based crime is detected and initially investigated not by the public bodies, but by private organizations, such as the APWG (an anti-phishing and cryptocurrency exchange), SPAMHAUS (the well-known anti-spam group), CAIDA (the Center for Applied Internet Data Analysis), anti-virus companies (such as Sophos, McAfee, Microsoft or Eset), or anti-ransomware groups. Unfortunately, being part of “everybody else” means that these organizations (“e-crime figthters”) (we need a sexy word to describe us) are following the same rules as marketing and tracking organizations, which do no e-crime fighting and should be constrained. Adding additional barriers to sharing e-crime data among public bodies and private organizations impedes the flow of that critical, very useful, data. Many senior law enforcement executives have expressly stated that they rely on private sector e-crimefighters participation and data sharing to perform their law-enforcement duties.
Conclusion
Developing a regulatory regime that gives the e-crime fighters to perform initial investigation, victim notification, event correlation, and data sharing with law enforcement while not allowing “everyone else” that ability will be a challenge. Some have suggested properly accreditation of the e-crime fighters may work; other ideas have surfaced but the perfect solution still awaits us.
There are many challenges to detect, investigate, and notify the proper authorities of e-crime activities at the same speed that the criminals do. We have identified two primary challenges and look forward to moving towards a solution.
The new European Union Privacy Regulations, fondly known as the GDPR (EU-2016/679) took effect in late May, 2018. If you listened to some crime fighters we would all be dead by now as the criminals would have taken over the world. And the Internet. We at the APWG try to reduce the amount of phishing and fraud on the internet. We have been working on understanding and preparing for compliance with the GDPR for over a year. It’s hard to understand, has lots of details to comply with, but definitely not the world ending event some have imagined.
If the regulation is so exacting, why is compliance so hard? From personal experience, many organizations legal and compliance teams are overworked; when new regulations appear the teams hope that there is also some guidance on how to comply and how soon – or a hint as to how severe- non-compliance will be.(If you don’t agree with me, you’ve never worked in a legal or compliance team.) So I’m taking a wild stab here, but from my experience there are three large issues:
Not all data sharing is contract-based nor covered by “binding corporate rules” as defined in the GDPR. The APWG’S Data Sharing Agreement (DSA) – a contract – was put in place to specify what parties taking our datasets could do with it. It made the sharing-field very level – everyone who sent us data or took data new exactly the boundaries of what they could do with the data. Many data sharing organizations, both formal and informal, are not contract-based and now need to quickly develop contracts.
When new regulations arrive, there is an amount of guesswork to figure out how to minimally comply with it. Most organizations do not want to violate the law, but new laws require new thinking, new paperwork, new processes, on how to comply with it. The EU and its members has not been very forthright in specifying how an organization could minimally or consistently comply with the regulation.
The regulation has onerous enforcement provisions. Although the EU or its members may not attack non-compliant organizations on day one, the regulations allows any EU natural person to bring enforcement action by themselves upon an organization. The volume and expense of these actions are all unknown making the previous bullet even harder.
Just my thoughts, but I bet I’m close to the target.
One of the important topics in fighting fraud and crime is data logistics, or the movement of IOCs, observations, and intelligence betwen cooperating entities. If you receive a phishing message and want to tell others about it to reduce the number of potential victims – you are using data logistics. If you receive so-called threat feeds, you are using data logistics. This process of collection, storage, and distribution is always hung up on a few main issues: 1) agreeing to common data formats; 2) convincing others of the benefits of sharing data, and 3) ensuring that the data sharing operations meet secrity, privacy, and disclosure regulations.
The APWG created a specific term, e-crime event data records, to identify the data pieces, streams, or records we collect and share using data logistics. Why make a new term? Technicrats can be pedantic. If we’re discussing indicators-of-compromise (IOCs), malicious scanning data, account takeover info (ATO) or anything else, we’re really talking about an event composed of some type of data record. Our focus is on data related to electronic crime so it’s e-crime event data records. No matter what detailed event data we’re discussing, it can be generally identified as e-crime event data , even if new data or crime type appear. Simplicity wins. Discussions with non-technocrats like governments and law enforcement agents also become easier with general terms.
Issue #1: Agree on Common Data Formats
The collected and shared data must be in a format that makes it easy for the collector and understandable by the reciever. In many cases, the data collector has one chance to do the collection. For example, a network operator has one chance to capture network traffic as it only comes by once. Historically, e-crime event data was exchanged via the simple csv format. Although a sheet full of csv data is easy to distribute, updating and correction is painful as one may have to reshare the entire data set. We have strived since 2004 to make data sharing easy and automated as manual processing does not scale well with large data sets.
We at the APWG have been pursuing a strategy that allows our members to collect and submit data in various formats, such as the IETF IODEF, that include critical elements and investigative hints. We suport other formats as necessary to ensure maximal data comprehension for the data reciver and conveys the critical information easily.
Issue #2: Convincing Others of the Benefits of Sharing Their Data Legally
Most people like it when others supply ecrime event data records. Many people have silly reasons why they can’t share their own data. (This is known as the 1/4/95 rule: One percent of people share their data and take others’ data; 4% just take others’ data and use it; 95% of the people take the data and don’t know what to do with it.)
The APWG helps our members explain the benefits of data sharing to their organizations and government regulators. We also host symposiums on identifying the reasons our members think they cannot share their ecrime event data records with us and their fellow crime fighters. Once identified, we help define procedures, policies, or guidance to reduce those impediments and increase ther amount of data sharing that we provide.
Issue #3: Ensuring our data sharing operations meet secrity, privacy, and disclosure regulations
The APWG, as an ecrime event data clearinghouse, endeavours to allow our members and other parties to collect and share data that helps the fight on crime. We help our members by defining common processes and expectations so data can be collected and shared anywhere in the world. A part of this effort is discussion and interaction with governments and international treaty partners to ensure we collect and share data in a consitent and legal manner. Our recent efforts include making our data sets EU GDPR compliant; working with ICANN to remove malicious domains from the DNS system; supporting efforts in the Council of Europe and the United Nations on data movement for the pursuit of crminal activity; and offering metrics and experiences to guide governmental thought. We plan to continue to be a leader in innovative way to solve the legal issues in data logistics.
Our data logistics blog contains our thoughts and plans on these, and other, data logistics and data sharing issues.
Many parties collect Internet event data such as data such as IP Addresses, originator identification, or communications content to track network congestion, comply with regulatory regimes, or to detect malicious activity. Many times the data collected is not truly ‘public’ data but has handling and distribution restrictions or caveats on it. The APWG shares some data that carries some further sharing restrictions and is currently exploring ways to mark this data. Most data or event sharing schemes include the ability to add a document sensitivity or classification marking to alert the recipient of the sensitivity of the data or its handling restrictions. For example, the IETF’s IODEF XML format has an attribute at the top-level to choose one of four sensitivity markings – ‘default’, ‘public’, ‘private’, and ‘need-to-know’. Those four choices are also available for marking specific sections of event logs or data, so a report can be marked with an overall sensitivity but have portions marked differently. Other data sharing formats (e.g., STIX, REN-ISAC) have equivalent functionality in the same or more – maybe 6 – markings. Other schemes have only three levels and invite creative combinations of the three values (e.g., TLP). As data exchanging becomes more automated the challenge is to devise a marking scheme that can be unambiguously interpreted by a machine – without the need for human assistance. As an example, one may receive 10,000 or so reports of malicious web sites every day. Human review to determine data sensitivity of the reports’ data items will significantly slow down the processing rate of the reports and possibly doom the data exchange. This paper presents a means to mark data to share within known groups that would support automation mechanisms.
2 The Problem
“The Problem” is really two distinct problems. First, a scheme is needed to properly mark data as it is received by the recipient to note its sensitivity. This (sensitivity) marking needs to be flexible enough to support a wide community of users, be not overly complicated to understand – particularly by automation systems, and be easily expandable as marks change and evolve over time. The sensitivity marks tell the recipient how to locally protect, and possibly re-share, the data. The second part of the problem is to devise a way to convey additional restrictions on the recipient. Both markings should unambiguously tell the recipient what they can do with the data after they receive it, for example, can they share it with others in their team or disclose details to other parties (who may be a victim of the event). There is no way for those two problems to be solved with a relatively small – four, six, or eight – set of identifiers. And there is even a slimmer chance that multiple data sharing communities could agree as to the definitions of those identifiers. The next sections introduce a way to deal with both of the identified problems. Note that our problem definition does not use these data sharing markings as a means to convey content sensitivity. Other marks are expected to be used for this purpose.
3 Our Data Sharing Model
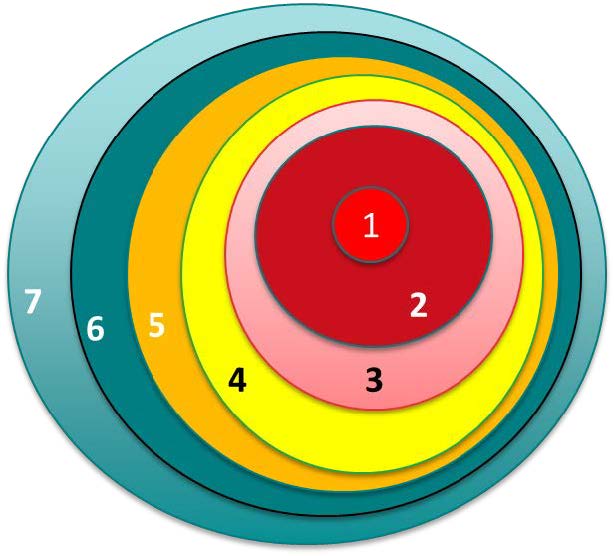
To understand our problem and possible solutions requires some understanding of how the APWG receives and distributes data. In short, the APWG is a data clearinghouse: very little processing of the received data is performed before the data is forwarded to others. Our goal is to be a common point of data collection to make it easier to collect data. The APWG forwards data to a set of recipients who are allowed to use the data for various purposes or to share the data further as explained in a contractual agreement. The purposes allowed to receivers of APWG data are roughly as follows. The data is: • only for the recipient’s use and should not be shared further. • may be shared with the recipient’s security team • may be shared with other members of the recipient’s organization • may be used in products • may be shared with other security groups • may be shared with the public Pictorially, the purposes can be shown as a set of concentric circles (as shown in figure 1), where each purpose is assigned a numerical value, such as: • 1 – ‘recipient only’ or ‘no further sharing’ • 2 – Coworkers in the security group • 3 – Data incorporated into products • 4 – Shared with affected users • 5 – Shared within the company • 6 – Forwarded to other security groups • 7 – Shared with the public
Figure 1.
Each circle includes the lower numbered circles There are more complex diagrams to show other relationships. For example, circle 2 could be split into two parts, one for friends of Pat (#2a) and one for enemies (#2b) of Pat. Data would be shared with the friends of Pat (#2a) but not his enemies (#2b). But the data could not be further shared as some enemies of Pat (in #2b) would get the data as part of circle #3 since the larger circles include the inner sets. Support for this more complex usage has been deferred until the concentric circle approach has been thoroughly tested.
4 The Requirements
Means to express both recipient and re-sharing constraints leads one to a small set of requirements.
The solution should inform the recipient of the data what they can do with it. For example, can they share it with others in their company, disclose it publicly, etc. This is called the “sharing tag”.
The solution should allow the sharer to add extra guidance, as in “Do not touch this system as it’s under surveillance”, or “Do not share it with Bob as we think he’s a bad guy” or even “Public disclosure is embargoed until Tuesday at dawn”. Recently the “share this data but don’t include attribution” has become fashionable as more sensitive data flows among parties. This extra guidance or cautionary detail to be considered when evaluating, interpreting, or doing something is called a “caveat”.
The apwg shares data between individuals, within groups, with other groups, and with the public. The solution needs to support all four without burdening the APWG operations staff.
The tags should be usable in multiple languages.
The tag should be easy to use in XML, CSV, or any other format-of-the-day.
The tags do not have to include all the policy implications of the data as sharing groups should have guidelines, maybe even contracts, to convey what the tags would imply. The sharing markings also do not have to convey data sensitivity marks. In many cases the “who can see it” implies certain sensitivities, and should be covered in the sharing group agreements.
5 Shoehorning Markings into Existing Structures
Our problem became visible when we started to share IODEF XML formatted data, which has four predefined tags. One solution was to redefine the restriction class in the IODEF schema to include other enumerations than the four defined in the standard. This has been tried with varying success. Many XML validation tools will mark the XML document as invalid since the IODEF schema doesn’t except the non-standard enumerations. In some cases the standard IODEF schema can be modified to get around this problem but that requires all tools used by data sharers to use the new schema and a new version of the standard to be produced. A second idea tried to redefine what the four classes meant, e.g., ‘public’ meant share with anyone, ‘restricted’ meant the recipient could share it with trusted parties, etc.. But it soon became evident that redefining the four markers would only add confusion as not everyone knew or agreed with the new interpretations. Ignoring the IODEF constraint issues and looking at other commonly-used schemes was not fruitful either. A current favourite marking scheme is based on the Traffic Light Protocol (TLP) which defines four levels of sharing and sensitivity. Although the levels are ‘red’ (no sharing), ‘amber’ (some sharing) and’ green’ (more sharing) and ‘white’ (no restrictions) there have been ‘black’ (which I infer as a burnt out traffic light) and confusion abounds as to what the actual colours mean for further re-sharing of the data. There isn’t enough information in four levels to support our sharing model, either, and although we could probably shoe-horn our groups into four levels there is still no way to add the localized caveats. A real concern is having data marked as ‘private’ or ‘amber’ by two different communities with different numbers of tags and unequal definitions of ‘private’ and conflicting handling caveats and no means-contractually or programmatically to equate them. More operational experience and study will be necessary to alleviate this concern.
6 A DataMarkings Structure
As existing marking schemes seem inappropriate to our needs, a totally new structure was designed to hold all the data marking information. The marking scheme is structured as an XML blob since that allows for some easy testing and validation but the structure should work in other formats. The thing, labeled ‘DataMarkings’, would contain a sequence of markings for a particular community. Each ‘community’ element includes sensitivity and sharing tag identifiers as defined by and for that community. Different communities could define their own equivalency rules to deal with data crossing group boundaries. For example, a dataMarkings structure that looks like:
would convey to a recipient that the data should be controlled and further shared as a level “3 – Friends” and a level “2 – Enemies of Pat” in the “apwg” community. Now, although the ‘2’ and the ‘3’ are the authoritative markers and are intended to help the automation systems, they may not have apparent meaning to a human so the could also be a defined data marking label like “no sharing outside group” or “sharing with public allowed”. The structure doesn’t need to know this detail. Additionally, there are some paranoid communities where the community name may be sensitive so the structure also allows any text to be used – e.g., community names generated by a hash or encryption or even random values. Communities are expected to provide guidance to their users on the use of the markings, caveats, and policy implications. The community string also carries a version identifier so communities can change, add, or remove markings without having to pick a different community name. The hope is that the version attribute will reduce the number of ‘apwg’, ‘apwg-1’, ‘apwg-2’ … ‘apwg-1367’ distinct community identifiers necessary in the future as the markings evolve. Some thought has been given to defining two other attributes – ‘until’ and ’after’ – to deal with embargoed data. For example, data may be ‘no sharing allowed’ until a point that an investigation is completed, then that data set becomes ‘share with trusted groups’. Although the XML additions are straightforward, it has not been made part of the class until development of an acceptable CONOPS and use case is complete. In real operations it may be easier to re-share the embargoed data with a new mark at the embargo expiration than to have to support complex caveat logic.
6.1 Hierarchical versus distinct markings
The structure supports hierarchical and distinct marking schemes although the first pilots use hierarchical marks.. A community could design their marks to be very specific, e.g., 0 – recipients, 1-friends of Pat, and 2 – friends of Bob. If we wanted to share with friends of Pat and friends of Bob the mark would need both an entry for’1’ and for ‘2’. There is no means to generate an “only trusted insiders” mark as it seems illogical as how would one know? The only case where this seems to make sense is to mark data as “only the infected system owner” if you are sharing the data with someone who has contact information for the infectee. The structure may be simplified if such a tag is really implemented as a caveat, which is our current plan.
7 Carrying Complex Markings into XML Documents
Another attribute of the community element is the ‘alias’ attribute. In IODEF and other XML formats, the generator of a report may mark specific parts of the report with more restrictive markings. For example, a spam report may mark the whole report with a ‘public’ mark but mark the element with a ‘good guys only’ as the history may include active investigative data. The alias attribute allows the report originator to designate a short-hand marking for use later in the document. A more complex example is:
Note that the class performs the same functions as the ‘shoehorning’ mentioned above, except by reusing existing enumerations there is no need to modify the existing IODEF or STIX schemas. The bad news is that there are still only four choices to ‘alias’ and the access control routines that process the report need to be aware of the equivalent markings. So although the structure supports it there are not many actual uses expected. Although proposed as more of a test feature, it has many advantages over adding additional structures and reissuing all the format standards.
8 New XML Data Classes
This section defines the structure as an XML-Document. Although it can be used in other formats XML allows for some testing and guided implementations.
8.1 The structure
The overall structure is two lists of values: BEGIN List of sharing tags (identifier, sharing-value) List of caveats (identifier, value) END The initial sharing tags in the APWG community, apwg-1, would be: 99 – Recipient only 83 – Community 73 – Internal Details 71 – Internal Summary 53 – Impacted Party Details 51 – Impacted Party Summary 43 – Used in Products 33 – Trusted Details 31 – Trusted Summary 11 – Public Summary 0 – No Restrictions This list supports our requirement to support the APWG sharing model in a hierarchical way. The numerical values were picked to allow easy (and fast) comparison in software and cardinality went from least restrictvie as a minimal value to the mst restrivtive being a numerically higher value to be consistent with the flow of some other known marking systems. A numerically lower value tag implies the higher values, so a tag value of 31 – Trusted Summary, implies that the data can be shared with the community (83) and internal groups (73) and every other group numerically larger than 31. Trying to define an initial set of caveats was more challenging. Although there are a number of sharing constraints it is unclear which of those constraints are valid in the APWG sharing model. An initial set of caveats are below but generating an acceptable caveat list will probably take quite some time . The use of non-numerical values should reduce confusion with tag values. NA – No originator attribution HI – Historical Data AI – Active Investigation, do not disturb or contact
8.2 A More International-Friendly Syntax
One concern is that non-English speakers may not adequately comprehend the descriptive portions of the sharing tags. A slight modification to the syntax could help this by modifying the descriptive portion of the tag, as in:
<tag>71 – Internal Summary</tag>
would change into <tag value=”71” lang=”en”>Internal Summary</tag> or for a Spanish version: <tag value=”71” lang=”sp”>Resumen interna</tag>
This new encoding would allow the descriptive field to be translated into local languages but the actual tag value would stay the same to optimize processing. Note that this modification would be useful for XML-encoded data markings where the extra bytes needed to encode the language tag do not significantly add to the length of the tag which is untrue for other non-XML encodings. Nevertheless, this is incorporated into the current dataMarkings structure definition.
9 XML Schema Definition
To help the tag definitions an XML schema is being developed. It is not final but is referenced here for information. The current XML schema is available at:
The following STIX-Document shows placement and an example use of the markings. Some fields have been compacted for display.
<STIX_Header>
<Title>Example Report for Scanning for open ssh servers</Title>
<Package_Intent xsi:type="stixVocabs:PackageIntentVocab-1.0">Indicators - Network Activity</Package_Intent>
<Profiles>
<stixCommon:Profile>apwg.org:scan-general-1</stixCommon:Profile>
</Profiles>
<Handling>
<marking:Marking>
<marking:Marking_Structure marking_model_ref="apwg1"
xsi:type="apwgMarkings:apwgMarkingStructureType">
<apwgMarkings:tag value =”00”>No Restrictions</apwgMarkings:tag>
</marking:Marking_Structure>
</marking:Marking>
</Handling>
<Information_Source>
…
11 Use in CSV formats
Although we specified the tags and caveats in XML they should work in CSV sharing communities. The community, tag, and caveats could be encoded as community/tag/caveats followed by a comma, as in ,apwg/71 – Internal Summary/NA – no attribution .
Some sharing communities may be able to specify shortcuts. If the community uses the apwg tags, and really wants to save space, the data marking could be ,71/NA, Other formats should be able to support our markings in a similar manner.
12 APWG Pilot Use
APWG researchers have proposed multiple communities for the collection and sharing of data and incorporated the marks into a test data repository. Some of the actual policy guidance to mark data are still under development and are repository and community dependent and the definitions are quite fluid; do not rely on them for operational use. The current XML schema and CSV guidance are available at github.com/patCain/ecrisp.
13 Further Considerations
The use of these marking is still in development and the operational situations are still evolving. Although a draft CONOPS is in the works, comments, suggestions for improvement, and operations models that break the concept are always appreciated –particularly if you share data in a compatible data model as the APWG’s.
14. References
Danyliw, R., Meijer, J., & Demchenko, Y. (2007, December). The Incident Object Description Exchange Format (RFC 5070). Retrieved January 2012, from Internet Engineering Task Force: ftp://ftp.isi.edu/in-notes/rfc5070.txt